
It has been awhile since I completed the UCSanDiegoX‘s Python for Data Science course on edX. I’m writing this post to remind myself what I have done: the course contents and the London air-bnb project.
This certificate course is by UCSanDiegoX and it consists of the Mini Project, the Final Project, and the Final Exam which is proctored. First, and foremost, you’ll learn how to conduct data science by learning how to analyze data.That includes knowing how to import data, explore it, analyze it, learn from it, visualize it, and ultimately generate easily shareable reports. We’ll also introduce you to two powerful areas of data analysis: machine learning and natural language processing.To conduct data analysis, you’ll learn a collection of powerful, open-source, tools including:
● Python
● Jupyter notebooks
● pandas
● NumPy
● Matplotlib
● scikit learn
● NLTK
And many other tools!And you won’t be learning these tools in isolation. You will learn these tools all within the context of solving compelling data science problems.
Topics covered and my comments:
- Data Science Introduction: The course starts with an introduction to data science, big data, how python is used for analyzing data and the exploration of a soccer data set. This section gives learners intuition on acquiring, exploring, per-processing and analyzing the data and then reporting the insights and helping the insights turn into action. I like the way they provide the learners introduction to the data science process and the value of learning data science.Also the setup process of jupyter notebooks was streamlined and super easy.
- Background in Python and Unix (optional) : This is an optional module which helps the learners who are not familiar with python or for the learners who are not from a computers background. They give an overview of python, the value of python in data science, python basics, python variables and UNIX. The lectures were easy to understand and this is one of the fundamental building blocks for data science. This module, according to me is very well taught and is easy to learn and sets you up for the course.
- Jupyter Notebooks and Numpy: In this section, we learn about jupyter notebooks- their working, analysis using markdown text, using UNIX in Jupyter Notebooks and numpy-ndarray basics, ndarray indexing, ndarray Data-types and Operations, numpy broadcasting and speed test of numpy and python lists and satallite image analysis (WIFIRE example). I think Jupyter Notebooks is a very user friendly editor with lots of functions and tricks up its sleeve. The power of jupyter notebooks and numpy is clearly visible through the satellite image analysis.
- Pandas: This module covers Pandas- Introduction, why to use pandas, data ingestion, descriptive statistics, data cleaning, data visualization, merging data-frames, parsing timestamps summary of Movie Rating Notebook .The lectures in this module are well taught as well as the live code makes it much easier to understand Pandas and also prepares the learners to well enough understand the data visualization that would be taught in the next module.
- Data Visualization: Data visualization is one of the most important topics in data analytics and this module has done enough to help you understand the visualizations and even create them in jupyter notebooks using matplotlib. This includes lectures on data visualization- role of data visualization, types of data visualization and key design principles and matplotlib- basic plotting using matplotlib (on world development indicators dataset), additional examples of matplotlib, folium example and two case studies- 1.Cholera 2. Napoleon’s March. An incredible job at explaining and teaching data visualization using matplot lib as well as introduces additional libraries used for data visualization.
- Introduction to Machine Learning: The course introduces the learner to Machine Learning, the categories of ML, the terminology related to ML and how to use scikit-learn i.e ML in python.This introduction sets up basis for the topics that are classification, clustering and regression analysis. These topics are also taught in the same module but I will talk about them as seperate topics because they are the basis of Machine Learning.
- Introduction to Machine Learning- Classification:Classification is the process of finding or discovering a model or function which helps in separating the data into multiple categorical classes i.e. discrete values.In this section we learn about Classification, how to build and apply a classification model, classification model using decision trees and how to use python to model a decision tree. The depth of the topics covered is not that much but well detailed for an introduction.
- Introduction to Machine Learning- Clustering: Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them. We learn about clustering, k-Means Clustering, and how to do clustering using python and jupyter notebooks.
- Introduction to Machine Learning- Regression Analysis: Regression is the process of finding a model or function for distinguishing the data into continuous real values instead of using classes or discrete values. These set of lectures guide us through regression analysis right form introducing it, its mechanism, linear regression and how build a linear regression model in python ( very well explained along with Live Code ). There were also lectures on how Machine Learning is used by experts in different fields.
- Working with Text and Databases- Introduction: In this module we are taught about working with text and databases, I have divided this module into 3 topics. Learners are introduced to relational data models, its structural components and the components which make up its schema, an introduction to Structured Query Language (SQL) and how to use SQL in jupyter notebooks using python. The topics are explained in detail with no confusion at all.
- Working with Text and Databases- Natural Language Processing with NLKT : Natural Language Processing (NLP) is a process of manipulating or understanding the text or speech by any software or machine. NLTK (Natural Language Toolkit) is a suite that contains libraries and programs for statistical language processing. It is one of the most powerful NLP libraries, which contains packages to make machines understand human language and reply to it with an appropriate response. This module introduces the learner to Natural Language Processing with nltk, different nltk libraries like nltk corpora, tokenize, how to build a Bag-of-Words Model, plotting the frequency of words and sentimental analysis on the data. NLP are widely used in chat-bots around the world and this was a good in-depth study of NLP with nltk and python.
- Working with Text and Databases- Twitter Working with Text: This section begins with a tutorial to access the Twitter API and authentication of the Twitter API in Python. After setting up the lectures along with live code guide us on how to explore twitter trends, explore twitter search and create frequency distributions. The lectures do a good job at providing in-depth information and enough practical knowledge to apply the taught topics.






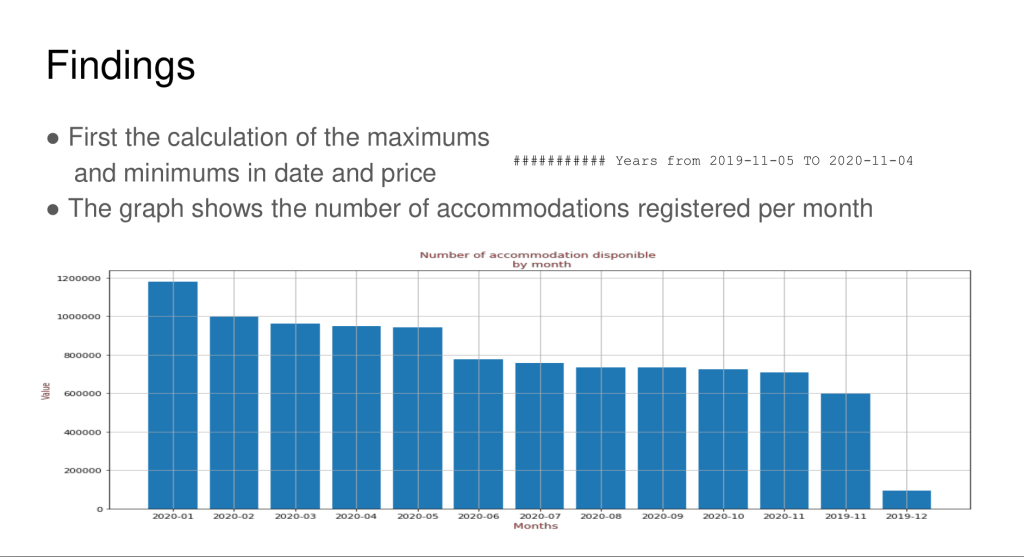
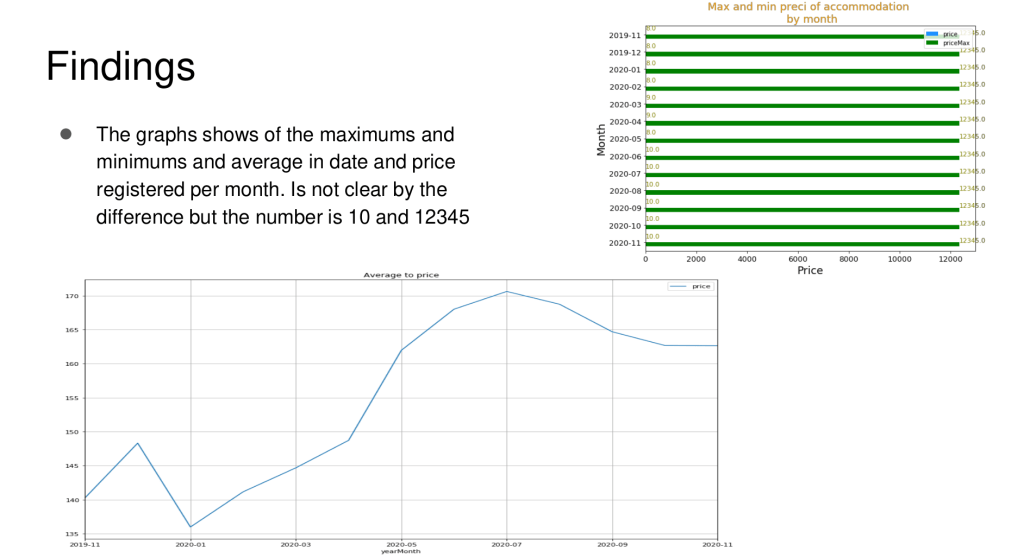
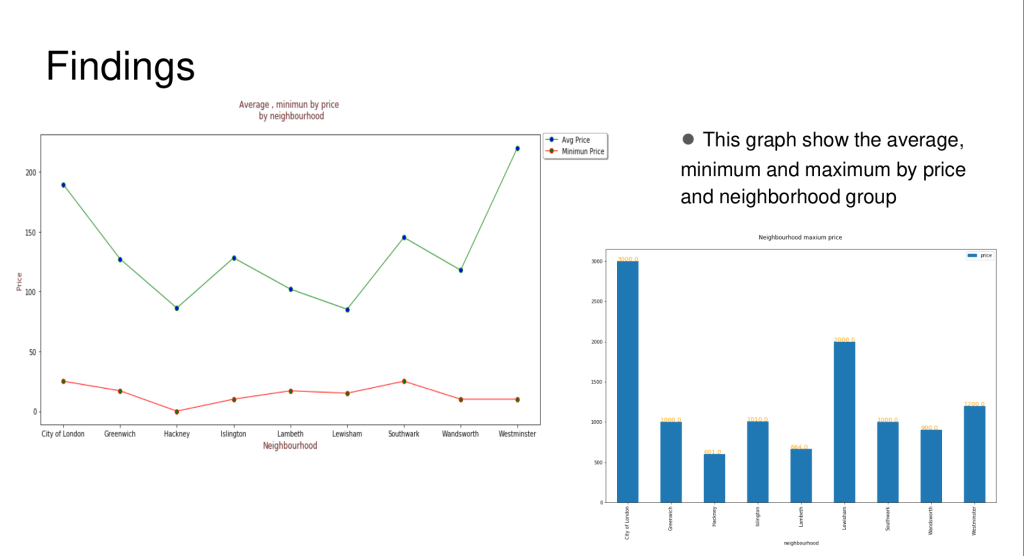
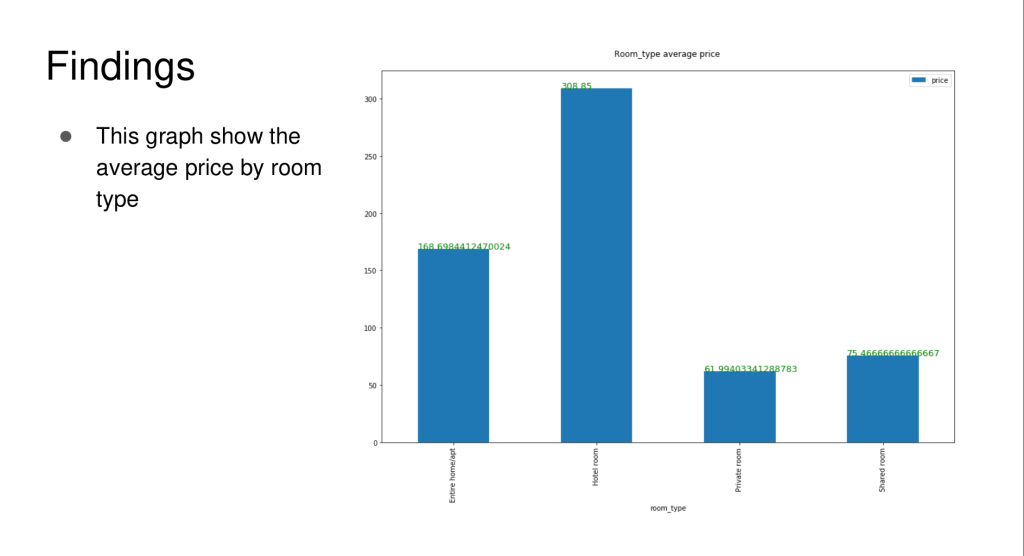
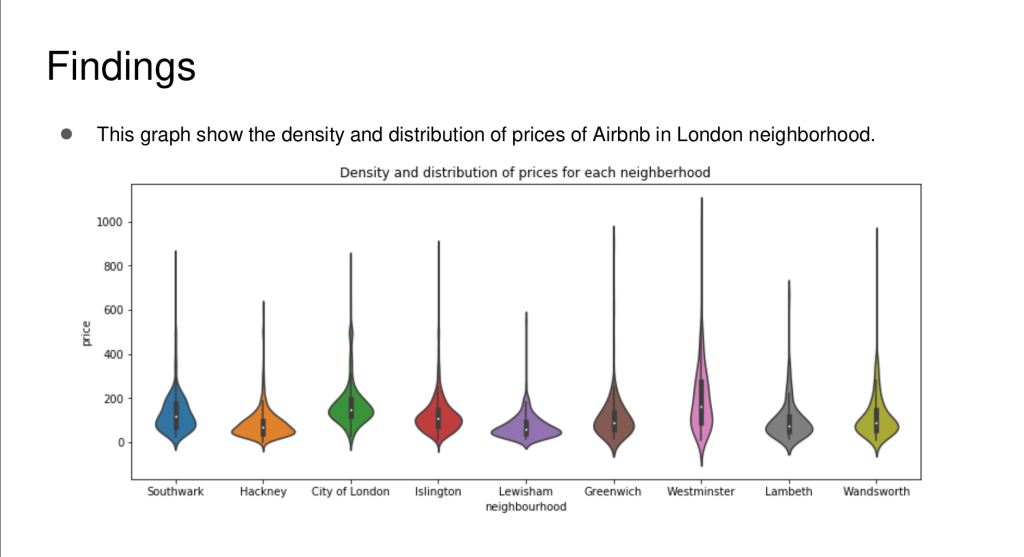






It was my first time having to code in Python and thankfully the lecture materials coupled with the hand-on experience was sufficient for me to learn the programming language. I was introduced to the world of machine learning with Python for the first time with the ML module. For the final project, I had to perform clustering of neighborhoods of London to determine whether the admission session of colleges affect the air-bnb rates and which neighborhood has the most no. Of air-bnb’s etc.The typical pandas library is used to process, explore and analyze the data. Finally, matplotlib library is used to visualize the data to communicate my results and findings.
Check out the course on edX @ https://www.edx.org/course/python-for-data-science-2?index=product&queryID=0414913ea215eaa28288aca9b00c9c0d&position=1
My course certificate! =D https://courses.edx.org/certificates/00d38e4499ad497b824ac13e3dcf40a0
That’s all! Thanks for reading!
I would like to use this opportunity to thank course instructor Ilkay Altintas & Leo Porter for hosting this course on edX. Thank you!
Starting 17th March 2021, I’ll try to write a blogpost once a week to remember and keep a record of the things I have done.
